本文是基于 从输入URL到页面加载的过程?如何由一道题完善自己的前端知识体系!![]() 的搬运和整理,主要是为了进一步巩固知识,感谢大佬,侵删。
的搬运和整理,主要是为了进一步巩固知识,感谢大佬,侵删。
Step1. 从浏览器接收URL到开启网络请求线程
首先要了解浏览器的多进程,其中渲染进程里又有许多线程去处理各个任务。
多进程的浏览器
主控进程:浏览器的主进程(负责协调、主控),只有一个
第三方插件进程:每种类型的插件对应一个进程,仅当使用该插件时才创建
GPU进程:最多一个,用于3D绘制
浏览器渲染进程(内核):默认每个Tab页面一个进程,互不影响,控制页面渲染,脚本执行,事件处理等(有时候会优化,如多个空白Tab会合并成一个进程)
多线程的浏览器渲染进程(内核)
GUI线程
JS引擎线程
事件触发线程
定时器线程
网络请求线程
解析URL
输入URL后,会进行解析(URL的本质就是统一资源定位符),URL的组成分为:
protocol:协议头,譬如有HTTP,ftp等host:主机域名或IP地址port:端口号path:目录路径query:即查询参数fragment:即#后的hash值,一般用来定位到某个位置
更多
Step2. 开启网络线程到发出一个完整的http请求
DNS查询得到IP
如果浏览器有缓存,直接使用浏览器缓存,否则使用本机缓存,再没有的话就是用
host如果本地没有,就向
DNS域名服务器查询(当然,中间可能还会经过路由,也有缓存等),查询到对应的IP
TCP/IP请求
建立连接:三次握手
浏览器向服务器发送想建立连接的请求(你好,可以认识一下吗)
服务器向浏览器发送同意建立连接的响应(你好,当然可以啊)
浏览器向服务器发送确认收到响应的请求,客户端和服务器建立连接(非常高兴认识你)
相互通信
浏览器向服务器发起一个请求网页资源的请求
服务器返回对应网页资源
浏览器渲染、构建网页,在构建网页的过程中,可能会继续请求
css、JavaScript等资源
断开连接:四次挥手(返回响应结果后,双方都没有请求时)
浏览器向服务器发送想断开连接的请求(我要走啦)
服务器向浏览器发送收到请求的响应(我知道啦)
服务器向浏览器发送断开连接的请求(可以了,我走啦)
浏览器断开连接并向服务器发送一个反馈请求,服务器收到后断开连接(好的,拜拜)
并发限制
浏览器对同一域名下并发的TCP连接是有限制的(2-10个不等)
而且在HTTP1.0中往往一个资源下载就需要对应一个TCP/IP请求
get和post的区别
get和post虽然本质都是TCP/IP,但两者除了在HTTP层面外,在TCP/IP层面也有区别。
get会产生一个TCP数据包,post两个:
get请求时,浏览器会把headers和data一起发送出去,服务器响应200(返回数据)post请求时,浏览器先发送headers,服务器响应100 continue, 浏览器再发送data,服务器响应200(返回数据)
这里的区别是specification(规范)层面,而不是implementation(对规范的实现)。
五层因特网协议
应用层(DNS, http):DNS解析成IP并发送http请求传输层(tcp, udp):建立tcp连接(三次握手)网络层(IP, ARP):IP寻址数据链路层(PPP):封装成帧物理层(利用物理介质传输比特流):物理传输(然后传输的时候通过双绞线,电磁波等各种介质)
Step3. 从服务器接收到请求到对应后台接收到请求
后台方面的知识,略。
By 负载均衡
对于大型的项目,由于并发访问量很大,所以往往一台服务器是吃不消的,其中一种方式是一般会有若干台服务器组成一个集群,然后配合反向代理实现负载均衡。
简单的说:
用户发起的请求都指向调度服务器(反向代理服务器,譬如安装了nginx控制负载均衡),然后调度服务器根据实际的调度算法,分配不同的请求给对应集群中的服务器执行,然后调度器等待实际服务器的HTTP响应,并将它反馈给用户。
By 后台处理
一般后台都是部署到容器中的,所以一般为:
容器接受到请求(如
tomcat容器)对应容器中的后台程序接收到请求(如
java程序)后台会有自己的统一处理,处理完后响应响应结果
详细地说:
一般有的后端是有统一的验证的,如安全拦截,跨域验证
如果这一步不符合规则,就直接返回了相应的
HTTP报文(如拒绝请求等)当验证通过后,才会进入实际的后台代码,此时是程序接收到请求,然后执行(譬如查询数据库,大量计算等等)
等程序执行完毕后,就会返回一个
HTTP响应包(一般这一步也会经过多层封装)将这个包从后端发送到前端,完成交互
By 后台和前台的HTTP交互
前后端交互时,HTTP报文作为信息的载体。
HTTP报文机构
通用头部
Request Url:请求的web服务器地址Request Method:请求方式有多种HTTP1.0定义了三种请求方法:GET,POST和HEAD方法。
以及几种Additional Request Methods:PUT、DELETE、LINK、UNLINKHTTP1.1定义了八种请求方法:GET、POST、HEAD、OPTIONS,PUT,DELETE,TRACE和CONNECT方法。
Status Code:请求的返回状态码,如200代表成功Remote Address:请求的远程服务器地址(会转为IP)
状态码
1XX 指示信息,表示请求已接收,继续处理
2XX 成功,表示请求已被成功接收、理解、接受
3XX 重定向,要完成请求必须进行更进一步的操作
4XX 客户端错误,请求有语法错误或请求无法实现
5XX 服务器端错误,服务器未能实现合法的请求
常用请求头(Request Headers)
Accept:接收类型,表示浏览器支持的MIME类型
(对标服务端返回的Content-Type)Accept-Encoding:浏览器支持的压缩类型,如gzip等,超出类型不能接收Content-Type:客户端发送出去实体内容的类型Cache-Control:指定请求和响应遵循的缓存机制,如no-cacheIf-Modified-Since:对应服务端的Last-Modified,用来匹配看文件是否变动,只能精确到1s之内,HTTP1.0中Expires:缓存控制,在这个时间内不会请求,直接使用缓存,HTTP1.0,而且是服务端时间Max-age:代表资源在本地缓存多少秒,有效时间内不会请求,而是使用缓存,HTTP1.1中If-None-Match:对应服务端的ETag,用来匹配文件内容是否改变(非常精确),HTTP1.1中Cookie:有Cookie并且同域访问时会自动带上Connection当浏览器与服务器通信时对于长连接如何进行处理,如keep-aliveHost:请求的服务器URLOrigin:最初的请求是从哪里发起的(只会精确到端口),Origin比Referer更尊重隐私Referer:该页面的来源URL(适用于所有类型的请求,会精确到详细页面地址,csrf拦截常用到这个字段)User-Agent:用户客户端的一些必要信息,如UA头部等
常用响应头(Response Headers)
Access-Control-Allow-Headers:服务器端允许的请求HeadersAccess-Control-Allow-Methods:服务器端允许的请求方法Access-Control-Allow-Origin:服务器端允许的请求Origin头部(譬如为*)Content-Type:服务端返回的实体内容的类型Date:数据从服务器发送的时间Cache-Control:告诉浏览器或其他客户,什么环境可以安全的缓存文档Last-Modified:请求资源的最后修改时间Expires:应该在什么时候认为文档已经过期,从而不再缓存它Max-age:客户端的本地资源应该缓存多少秒,开启了Cache-Control后有效ETag:请求变量的实体标签的当前值Set-Cookie:设置和页面关联的Cookie,服务器通过这个头部把Cookie传给客户端Keep-Alive:如果客户端有keep-alive,服务端也会有响应(如timeout=38)Server:服务器的一些相关信息
请求/响应实体
HTTP请求时,除了头部,还有消息实体,一般来说
请求实体中会将一些需要的参数都放入进入(用于post请求)。
譬如实体中可以放参数的序列化形式(a=1&b=2这种),或者直接放表单对象(Form Data对象,上传时可以夹杂参数以及文件),等等
而一般响应实体中,就是放服务端需要传给客户端的内容
一般现在的接口请求时,实体中就是对于的信息的json格式,而像页面请求这种,里面就是直接放了一个html字符串,然后浏览器自己解析并渲染。
CRLF
CRLF(Carriage-Return Line-Feed),意思是回车换行,一般作为分隔符存在
请求头和实体消息之间有一个CRLF分隔,响应头部和响应实体之间用一个CRLF分隔
某HTTP报文结构的简要分析

Cookie以及优化
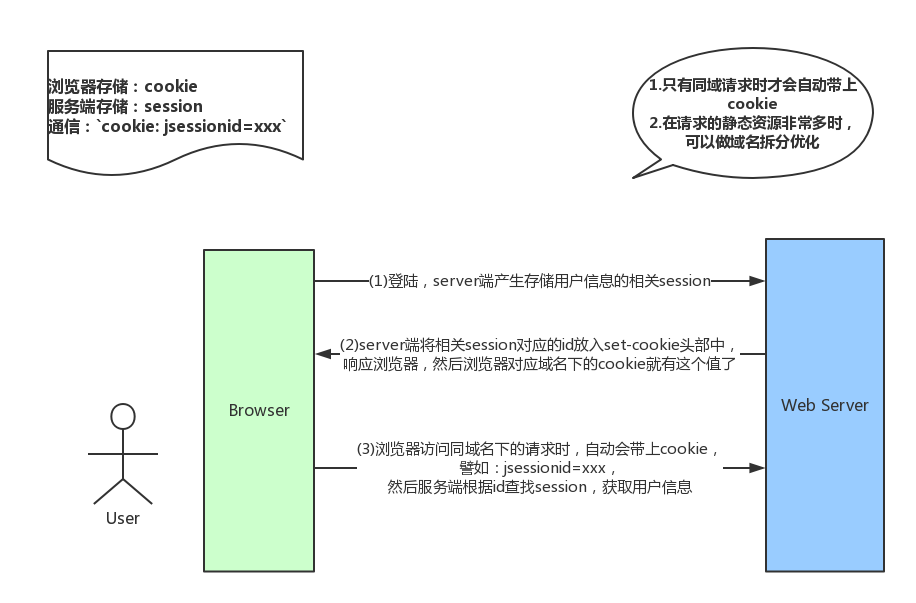
Cookie是浏览器的一种本地存储方式,一般用来帮助客户端和服务端通信的,常用来进行身份校验,结合服务端的Session使用。
常用使用场景简述:
在登录页面,用户登录了
此时,服务端会生成一个
Session,Session中有对于用户的信息(如用户名、密码等)然后会有一个
sessionid(相当于是服务端的这个Session对应的key)然后服务端在登录页面中写入
Cookie,值就是:jsessionid=xxx然后浏览器本地就有这个
Cookie了,以后访问同域名下的页面时,自动带上Cookie,自动检验,在有效时间内无需二次登录。
一般来说,Cookie是不允许存放敏感信息的(千万不要明文存储用户名、密码),因为非常不安全,如果一定要强行存储,首先,一定要在Cookie中设置httponly(这样就无法通过js操作了),另外可以考虑rsa等非对称加密(因为实际上,浏览器本地也是容易被攻克的,并不安全)
另外,由于在同域名的资源请求时,浏览器会默认带上本地的Cookie,针对这种情况,在某些场景下是需要优化的。
譬如以下场景:
客户端在域名A下有
Cookie(这个可以是登录时由服务端写入的)然后在域名A下有一个页面,页面中有很多依赖的静态资源(都是域名A的,譬如有20个静态资源)
此时就有一个问题,页面加载,请求这些静态资源时,浏览器会默认带上
Cookie也就是说,这20个静态资源的
HTTP请求,每一个都得带上Cookie,而实际上静态资源并不需要Cookie验证此时就造成了较为严重的浪费,而且也降低了访问速度(因为内容更多了)
针对这种场景,可以进行多域名拆分优化:
将静态资源分组,分别放到不同的域名下(如
static.base.com)而
page.base.com(页面所在域名)下请求时,是不会带上static.base.com域名的Cookie的,所以就避免了浪费
但是进行了多域名拆分,在移动端,如果请求的域名数过多,会降低请求速度(因为域名整套解析流程是很耗费时间的,而且移动端一般带宽都比不上pc)。
此时就需要用到一种优化方案:dns-prefetch(让浏览器空闲时提前解析DNS域名,不过也请合理使用,勿滥用)。
cookie总结
gzip压缩
首先,明确gzip是一种压缩格式,需要浏览器支持才有效(不过一般现在浏览器都支持), 而且gzip压缩效率很好(高达70%左右)
然后gzip一般是由apache、tomcat等web服务器开启
当然服务器除了gzip外,也还会有其它压缩格式(如deflate,没有gzip高效,且不流行)
所以一般只需要在服务器上开启了gzip压缩,然后之后的请求就都是基于gzip压缩格式的, 非常方便。
长连接与短连接
长连接的定义:一个TCP/IP连接上可以连续发送多个数据包,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接,一般需要自己做在线维持(类似于心跳包)。
短连接的定义:通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接。
HTTP1.0中,默认使用的是短连接,也就是说,浏览器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接,譬如每一个静态资源请求时都是一个单独的连接
HTTP1.1起,默认使用长连接,使用长连接会有这一行Connection: keep-alive,在长连接的情况下,当一个网页打开完成后,客户端和服务端之间用于传输HTTP的TCP连接不会关闭,如果客户端再次访问这个服务器的页面,会继续使用这一条已经建立的连接
HTTP 2.0
HTTP2.0不是HTTPS,它相当于是HTTP的下一代规范(譬如HTTPS的请求可以是HTTP2.0规范的)。
HTTP2.0和HTTP1.1的不同之处:
HTTP1.1中,每请求一个资源,都是需要开启一个TCP/IP连接的,所以对应的结果是,每一个资源对应一个TCP/IP请求,由于TCP/IP本身有并发数限制,所以当资源一多,速度就显著慢下来HTTP2.0中,一个TCP/IP请求可以请求多个资源,也就是说,只要一次TCP/IP请求,就可以请求若干个资源,分割成更小的帧请求,速度明显提升。
所以,如果HTTP2.0全面应用,很多HTTP1.1中的优化方案就无需用到了(譬如打包成精灵图,静态资源多域名拆分等)
然后简述下HTTP2.0的一些特性:
多路复用(即一个
TCP/IP连接可以请求多个资源)首部压缩(
HTTP头部压缩,减少体积)二进制分帧(在应用层跟传送层之间增加了一个二进制分帧层,改进传输性能,实现低延迟和高吞吐量)
服务器端推送(服务端可以对客户端的一个请求发出多个响应,可以主动通知客户端)
请求优先级(如果流被赋予了优先级,它就会基于这个优先级来处理,由服务器决定需要多少资源来处理该请求。)
HTTPS
HTTPS就是安全版本的HTTP,譬如一些支付等操作基本都是基于HTTPS的,因为HTTP请求的安全系数太低了。
简单来看,HTTPS与HTTP的区别就是: 在请求前,会建立SSL链接,确保接下来的通信都是加密的,无法被轻易截取分析
一般来说,如果要将网站升级成HTTPS,需要后端支持(后端需要申请证书等),然后HTTPS的开销也比HTTP要大(因为需要额外建立安全链接以及加密等),所以一般来说HTTP2.0配合HTTPS的体验更佳(因为HTTP2.0更快了)
一般来说,主要关注的就是SSL/TLS的握手流程,如下:
浏览器请求建立
SSL链接,并向服务端发送一个随机数–Client random和客户端支持的加密方法,比如RSA加密,此时是明文传输。服务端从中选出一组加密算法与
Hash算法,回复一个随机数–Server random,并将自己的身份信息以证书的形式发回给浏览器
(证书里包含了网站地址,非对称加密的公钥,以及证书颁发机构等信息)浏览器收到服务端的证书后
验证证书的合法性(颁发机构是否合法,证书中包含的网址是否和正在访问的一样),如果证书信任,则浏览器会显示一个小锁头,否则会有提示
用户接收证书后(不管信不信任),浏览会生产新的随机数
–Premaster secret,然后证书中的公钥以及指定的加密方法加密Premaster secret,发送给服务器。利用
Client random、Server random和Premaster secret通过一定的算法生成HTTP链接数据传输的对称加密key-Session key使用约定好的
HASH算法计算握手消息,并使用生成的Session key对消息进行加密,最后将之前生成的所有信息发送给服务端。
服务端收到浏览器的回复
利用已知的加解密方式与自己的私钥进行解密,获取
Premaster secret和浏览器相同规则生成
Session key使用
Session key解密浏览器发来的握手消息,并验证Hash是否与浏览器发来的一致使用
Session key加密一段握手消息,发送给浏览器
浏览器解密并计算握手消息的
HASH,如果与服务端发来的HASH一致,此时握手过程结束,
之后所有的HTTPS通信数据将由之前浏览器生成的Session key并利用对称加密算法进行加密
By HTTP缓存
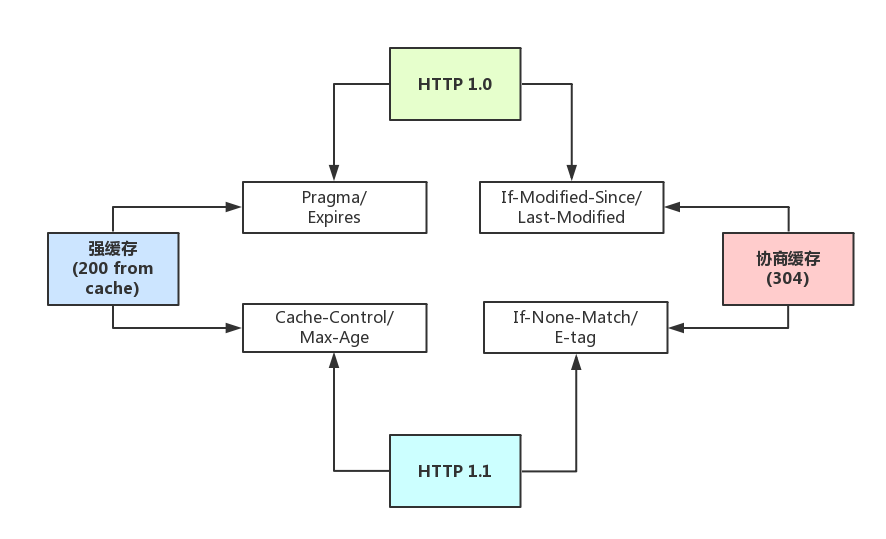
强缓存与弱缓存
强缓存(200 from cache)时,浏览器如果判断本地缓存未过期,就直接使用,无需发起http请求
协商缓存(304)时,浏览器会向服务端发起HTTP请求,然后服务端告诉浏览器文件未改变,让浏览器使用本地缓存。
对于协商缓存,使用Ctrl + F5强制刷新可以使得缓存无效
但是对于强缓存,在未过期时,必须更新资源路径才能发起新的请求(更改了路径相当于是另一个资源了,这也是前端工程化中常用到的技巧)
强缓存和协商缓存是通过不同的http头部控制。
头部的区别
HTTP1.0中的缓存控制:
Pragma:严格来说,它不属于专门的缓存控制头部,但是它设置no-cache时可以让本地强缓存失效(属于编译控制,来实现特定的指令,主要是因为兼容HTTP1.0,所以以前又被大量应用)Expires:服务端配置的,属于强缓存,用来控制在规定的时间之前,浏览器不会发出请求,而是直接使用本地缓存,注意,Expires一般对应服务器端时间,如Expires:Fri, 30 Oct 1998 14:19:41If-Modified-Since/Last-Modified:这两个是成对出现的,属于协商缓存的内容,其中浏览器的头部是If-Modified-Since,而服务端的是Last-Modified,它的作用是,在发起请求时,如果If-Modified-Since和Last-Modified匹配,那么代表服务器资源并未改变,因此服务端不会返回资源实体,而是只返回头部,通知浏览器可以使用本地缓存。Last-Modified,顾名思义,指的是文件最后的修改时间,而且只能精确到1s以内
HTTP1.1中的缓存控制:
Cache-Control:缓存控制头部,有no-cache、max-age等多种取值Max-Age:服务端配置的,用来控制强缓存,在规定的时间之内,浏览器无需发出请求,直接使用本地缓存,注意,Max-Age是Cache-Control头部的值,不是独立的头部,譬如Cache-Control: max-age=3600,而且它值得是绝对时间,由浏览器自己计算If-None-Match/E-tag:这两个是成对出现的,属于协商缓存的内容,其中浏览器的头部是If-None-Match,而服务端的是E-tag,同样,发出请求后,如果If-None-Match和E-tag匹配,则代表内容未变,通知浏览器使用本地缓存,和Last-Modified不同,E-tag更精确,它是类似于指纹一样的东西,基于FileEtag INode Mtime Size生成,也就是说,只要文件变,指纹就会变,而且没有1s精确度的限制。
Max-Age相比Expires?
Expires使用的是服务器端的时间
但是有时候会有这样一种情况:客户端时间和服务端不同步
那这样,可能就会出问题了,造成了浏览器本地的缓存无用或者一直无法过期
所以一般HTTP1.1后不推荐使用Expires
而Max-Age使用的是客户端本地时间的计算,因此不会有这个问题
因此推荐使用Max-Age。
注意,如果同时启用了Cache-Control与Expires,Cache-Control优先级高。
E-tag相比Last-Modified?
Last-Modified:
表明服务端的文件最后何时改变的
它有一个缺陷就是只能精确到1s,
然后还有一个问题就是有的服务端的文件会周期性的改变,导致缓存失效
E-tag:
是一种指纹机制,代表文件相关指纹
只有文件变才会变,也只要文件变就会变,
也没有精确时间的限制,只要文件一遍,立马
E-tag就不一样了
如果同时带有E-tag和Last-Modified,服务端会优先检查E-tag。
各缓存头部的关系
Step4. 客户端解析页面
流程简述
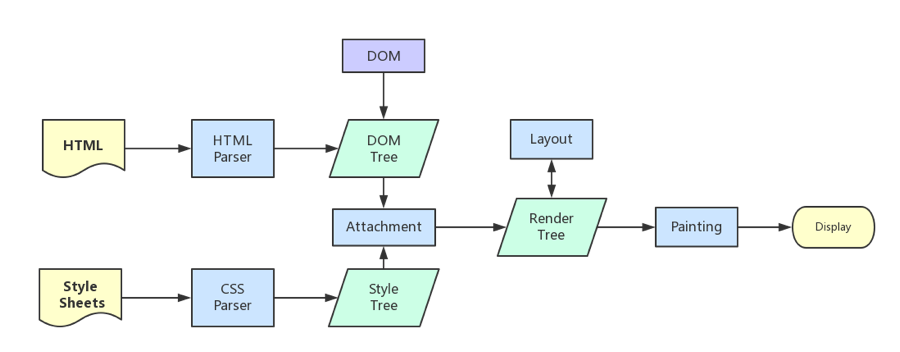
浏览器内核拿到内容后,渲染步骤大致可以分为以下几步:
解析
HTML,构建DOM树解析
CSS,生成CSS规则树合并
DOM树和CSS规则,生成render树布局
render树(Layout/reflow),负责各元素尺寸、位置的计算绘制
render树(paint),绘制页面像素信息浏览器会将各层的信息发送给
GPU,GPU会将各层合成(composite),显示在屏幕上
如下图:
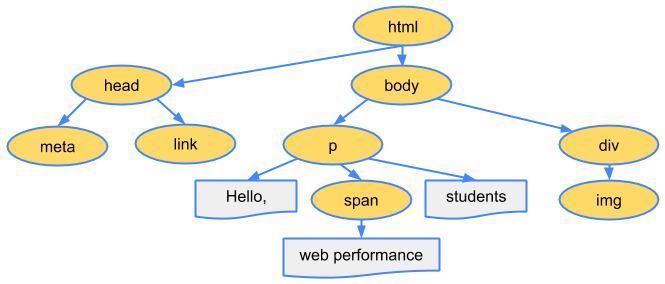
1.解析HTML,构建DOM树
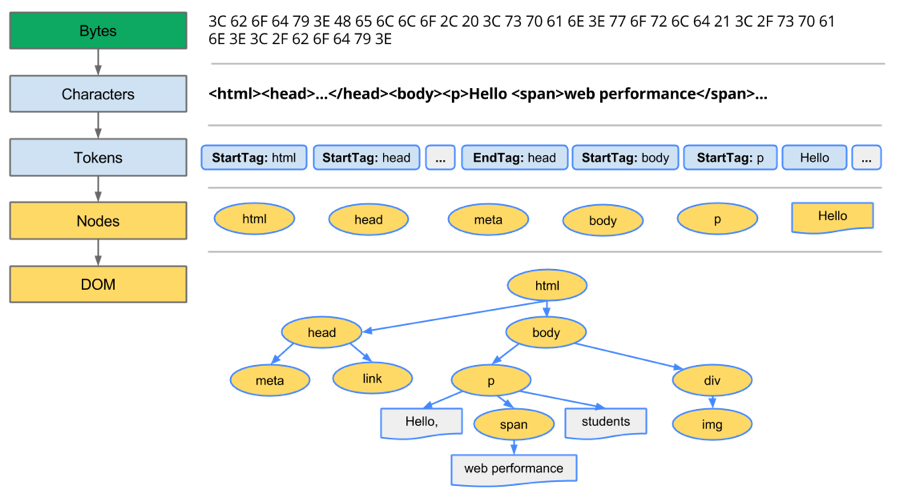
浏览器处理流程如下图:
其中的一些重点过程:
Conversion转换:浏览器将获得的HTML内容(Bytes)基于他的编码转换为单个字符Tokenizing分词:浏览器按照HTML规范标准将这些字符转换为不同的标记token。每个token都有自己独特的含义以及规则集Lexing词法分析:分词的结果是得到一堆的token,此时把他们转换为对象,这些对象分别定义他们的属性和规则DOM构建:因为HTML标记定义的就是不同标签之间的关系,这个关系就像是一个树形结构一样
例如:body对象的父节点就是HTML对象,然后段略p对象的父节点就是body对象
最后的DOM树如下:
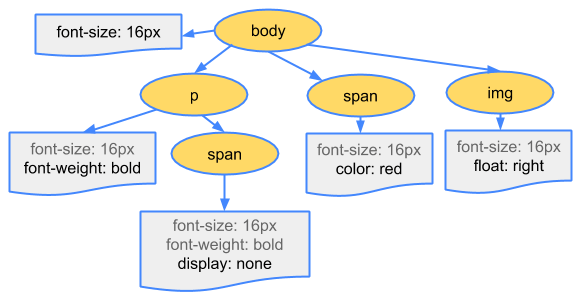
2.构建CSSOM树
Bytes → characters → tokens → nodes → CSSOM
假如style.css内容如下:
1 | body { |
那么最终的CSSOM树就是:
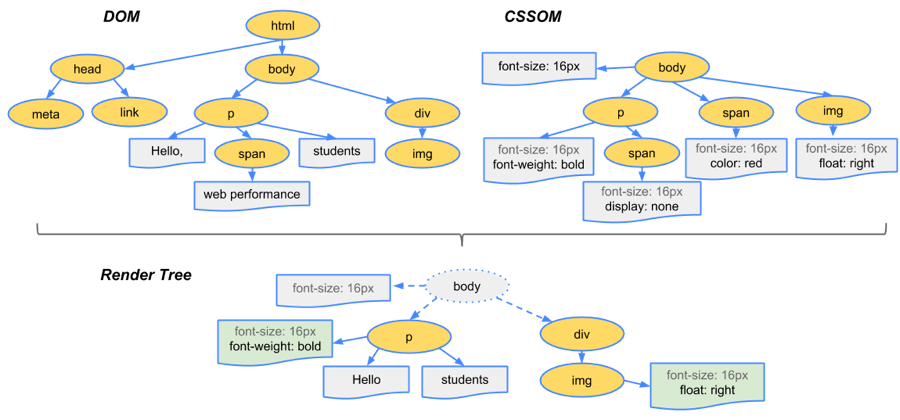
3.构建render树
当DOM树和CSSOM都有了后,就要开始构建render树了
一般来说,render树和DOM树相对应的,但不是严格意义上的一一对应
因为有一些不可见的DOM元素不会插入到render树中,如head这种不可见的标签或者display: none等
整体来说可以看图:
4.布局和绘制render树(渲染)
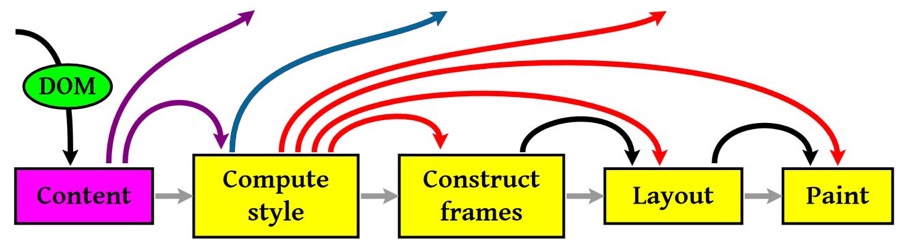
图中重要的四个步骤就是:
计算
CSS样式构建渲染树
布局,主要定位坐标和大小,是否换行,各种
positionoverflowz-index属性绘制,将图像绘制出来
然后,图中的线与箭头代表通过js动态修改了DOM或CSS,导致了重新布局(Layout)或渲染(Repaint)
Layout和Repaint的区别:
Layout,也称为Reflow,即回流。一般意味着元素的内容、结构、位置或尺寸发生了变化,需要重新计算样式和渲染树Repaint,即重绘。意味着元素发生的改变只是影响了元素的一些外观之类的时候(例如,背景色,边框颜色,文字颜色等),此时只需要应用新样式绘制这个元素就可以了
回流的成本开销要高于重绘,而且一个节点的回流往往回导致子节点以及同级节点的回流, 所以优化方案中一般都包括,尽量避免回流。
引起回流的几种方式
页面渲染初始化
DOM结构改变,比如删除了某个节点render树变化,比如减少了padding窗口
resize最复杂的一种:获取某些属性,引发回流,很多浏览器会对回流做优化,会等到数量足够时做一次批处理回流,但是除了
render树的直接变化,当获取一些属性时,浏览器为了获得正确的值也会触发回流,这样使得浏览器优化无效,包括:offset(Top/Left/Width/Height)scroll(Top/Left/Width/Height)cilent(Top/Left/Width/Height)width,height- 调用了
getComputedStyle()或者IE的currentStyle
改变字体大小
回流一定伴随着重绘,重绘却可以单独出现
避免回流的一些优化方案,如:
减少逐项更改样式,最好一次性更改
style,或者将样式定义为class并一次性更新避免循环操作
dom,创建一个documentFragment或div,在它上面应用所有DOM操作,最后再把它添加到window.document避免多次读取
offset等属性。无法避免则将它们缓存到变量将复杂的元素绝对定位或固定定位,使得它脱离文档流,否则回流代价会很高
5.将渲染的DOM显示到屏幕上
上述中的渲染中止步于绘制,但实际上绘制这一步也没有这么简单,它可以结合复合层和简单层的概念来讲。
简单介绍下:
可以认为默认只有一个复合图层,所有的
DOM节点都是在这个复合图层下的如果开启了硬件加速功能,可以将某个节点变成复合图层
复合图层之间的绘制互不干扰,由
GPU直接控制而简单图层中,就算是
absolute等布局,变化时不影响整体的回流,但是由于在同一个图层中,仍然是会影响绘制的,因此做动画时性能仍然很低。而复合层是独立的,所以一般做动画推荐使用硬件加速
更多
Chrome中的调试
Chrome开发者工具-Perfomance查看详细渲染过程:
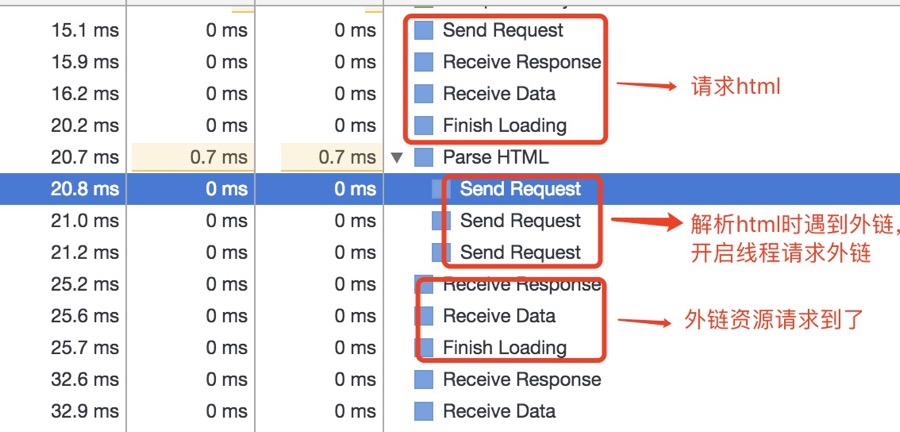
资源外链的下载(JS、CSS、IMG等)
上面介绍了html解析,渲染流程。但实际上,在解析html时,会遇到一些资源连接,此时就需要进行单独处理了
简单起见,这里将遇到的静态资源分为一下几大类(未列举所有):
CSSJavaScriptimg
遇到外链时的处理
当遇到上述的外链时,会单独开启一个下载线程去下载资源(HTTP1.1中是每一个资源的下载都要开启一个HTTP请求,对应一个TCP/IP链接)
遇到CSS样式资源
css下载时异步,不会阻塞浏览器构建DOM树但是会阻塞渲染,也就是在构建
render时,会等到css下载解析完毕后才进行(这点与浏览器优化有关,防止css规则不断改变,避免了重复的构建)有例外,
media query声明的CSS是不会阻塞渲染的
遇到JS脚本资源
阻塞浏览器的解析,也就是说发现一个外链脚本时,需等待脚本下载完成并执行后才会继续解析
HTML浏览器的优化,一般现代浏览器有优化,在脚本阻塞时,也会继续下载其它资源(当然有并发上限),但是虽然脚本可以并行下载,解析过程仍然是阻塞的,也就是说必须这个脚本执行完毕后才会接下来的解析,并行下载只是一种优化而已
defer与async,普通的脚本是会阻塞浏览器解析的,但是可以加上defer或async属性,这样脚本就变成异步了,可以等到解析完毕后再执行
注意,defer和async是有区别的: defer是延迟执行,而async是异步执行。
async是异步执行,异步下载完毕后就会执行,不确保执行顺序,一定在onload前,但不确定在DOMContentLoaded事件的前或后defer是延迟执行,在浏览器看起来的效果像是将脚本放在了body后面一样(虽然按规范应该是在DOMContentLoaded事件前,但实际上不同浏览器的优化效果不一样,也有可能在它后面)
遇到img图片类资源
遇到图片等资源时,直接就是异步下载,不会阻塞解析,下载完毕后直接用图片替换原有src的地方
loaded和domcontentloaded
区别:
DOMContentLoaded事件触发时,仅当DOM加载完成,不包括样式表,图片(譬如如果有async加载的脚本就不一定完成)load事件触发时,页面上所有的DOM,样式表,脚本,图片都已经加载完成了